
(Image generated by AI)
How default probability analytics can make a difference
- Default Probability is a crucial concept in credit risk analytics.
- Kamakura provides default probability measures for public firms, non-public firms, US banks, and sovereign counterparties.
- Default probability management means longer likelihood of stability for financial service providers like banks.
Predictive decisions are always made based on the data and variables that are available. Economies around the world continue to analyze data available to them to predict market outcomes and guide the likes of interest rates, on which those economies depend for their continuation. But the thing about predictions is that they will always remain predictions, rather than certainties. Probabilities can, and do, still go either way.
Technology is now slowly changing this, though. While AI has made a difference to businesses by automating processes, it is also capable of studying data to provide insights. These predictive analytics are the process of using data to forecast future outcomes. By using data analysis, machine learning, AI and statistical models, businesses can find patterns that might accurately predict future behavior.


The use of data to predict outcomes is at the core of the financial world. Analysts and economists have been using various models and calculations to predict marketbehaviors for decades. While they do hit the mark, most times, the process can be long and tedious.
At the same time, there is also default probability analytics. Default probability is a crucial concept in credit risk analytics. It quantifies the likelihood that a borrower or counterparty will default on their financial obligations within a specified time frame. Expressed as a percentage, it represents the probability of a credit event occurring.
Here’s how it works:
- Data Collection: Relevant data about borrowers and their credit performance is collected. This includes financial statements, credit bureau reports, loan repayment history, and other relevant factors.
- Data Pre-processing: The collected data is cleaned and prepared for analysis by removing duplicates, correcting errors, and addressing missing values.
- Variable Selection: A set of predictive variables (features) is chosen based on their relevance to default prediction. These variables include financial ratios, credit scores, industry indicators, macroeconomic factors, and other relevant information.
- Model Development: Statistical models are built to estimate the probability of default. These models use historical data and consider financial health, credit history, and economic conditions.
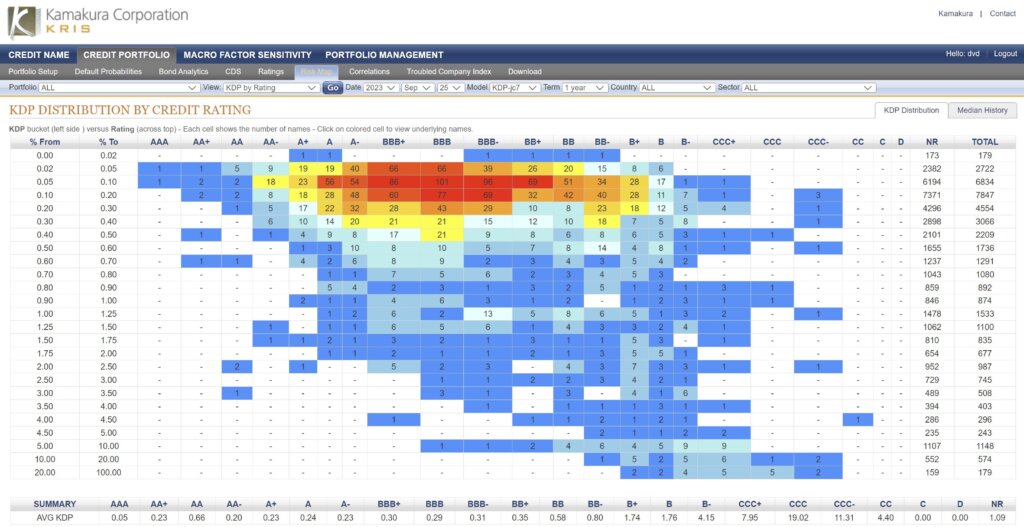
What the risk map looks like. (Source – Kamakura).
SAS and Kamakura
This is where companies like SAS and Kamakura come in. Having acquired the risk management software, SAS now provides an unparalleled suite of integrated risk solutions, particularly concerning asset liability management (ALM) and other essential solutions for the financial services industry. SAS has scaled resources to support Kamakura products, enabling SAS resources and selected specialized partners.
For default probability analytics, Kamakura provides default probability measures for public firms, non-public firms, US banks, and sovereign counterparts which can be used to assess the creditworthiness of an entire credit portfolio or on a single name basis. Inputs to the Kamakura models include company-specific attributes, industry-related measures and relevant macro-economic factors. Independent tests have confirmed that Kamakura default probabilities have the highest-performing predictive power available in the market.


According to Donald R. Van Deventer, the founder of Kamakura, the software product is Kamakura Risk Manager. It’s an enterprise-wide Risk Management System (KRIS) that integrates market risk, asset liability management, credit risks, transfer, pricing, capital allocation, and many other variables. Van Deventer stated that the alliance with SAS, especially with the SAS Viya platform, makes the hosting of Kamakura Risk Manager (KRM) seamless, and facilitates the integration of KRM with other products.
Specifically, KRIS default probabilities are updated daily for 40,500 firms in 76 countries, for more than 4,900 US banks insured by the FDIC, and for 183 sovereigns. The legacy rating agencies update ratings on only 3-6 corporate families per day. Worldwide, only around 2,650 corporate families have ratings.
The solution works by considering the average percentile wreck of the defaulting observations. Put simply, it’s the universe of default probabilities of the observations that did not default.
“We value every traded corporate bond in the US corporate market every day. So the best way to measure accuracy is not to make up some absolute standard. For the Challenger model, we’ve chosen a rating base valuation model, where every day, we ask the question, what credit spread best fits all the bonds with a triple eight rate or what credit spread fits the bonds with a double A plus, and so on,” explained Van Deventer.
Kamakura’s Implied Rating model provides a most likely legacy rating agency rating for a public firm based on company-specific attributes, Kamakura default probabilities, industry classification and relevant macro-economic factors along with the historical behavior of the legacy rating agencies.
Bonds. (Source – Kamakura).
Default probability analytics: the opportunity in Southeast Asia
Van Deventer was recently in Southeast Asia, speaking to banks and potential customers about the benefits of using this model. In fact, he believes the region has a lot to gain, given the amount of data available.
“People in the region are very smart. People realize how much volatility in the region is coming out of China, both political and economic. And they need to have a tool that can immediately respond if China does something strange. I don’t have the probability for political acts by China or any country although we do have a sovereign risk estimate for China. And the fall probably we see from China is higher than any other country in the region with around 3% annual rate,” he explained.
What this means is that financial services in the region, especially the banks, would be able to use the model to predict their market in the future. By using KRIS, banks will have a very multinational database to bear.
“Blind, stupid, doodah, clueless luck!” – Sure, but imagine if you had the power, and the data, to accurately predict every toin coss of investment or financial provision. Welcome to default probability analytics.
READ MORE
- 3 Steps to Successfully Automate Copilot for Microsoft 365 Implementation
- Trustworthy AI – the Promise of Enterprise-Friendly Generative Machine Learning with Dell and NVIDIA
- Strategies for Democratizing GenAI
- The criticality of endpoint management in cybersecurity and operations
- Ethical AI: The renewed importance of safeguarding data and customer privacy in Generative AI applications