
Micron Technology has begun sampling the industry’s first 8-high 24GB HBM3 Gen2 memory, up to a 50% improvement over shipping HBM3 solutions. Source: Shutterstock
Micron Technology will release the most advanced HBM by 2024 to speed up AI training
- Micron Technology has begun sampling the industry’s first 8-high 24GB HBM3 Gen2 memory, up to a 50% improvement over shipping HBM3 solutions.
- These improvements reduce training times of large language models like GPT-4 and beyond while delivering efficient infrastructure use for AI inference.
- This will be followed by the unveiling of a 12-high stack with 36GB capacity, which will begin sampling in the first quarter of 2024.
The demand for high bandwidth memory (HBM) is taking off, thanks to OpenAI’s ChatGPT, which has led to a surge in generative AI servers. US memory chip giant Micron Technology, a tad behind its large competitors regarding HBM, has just unveiled its newest version, an 8-high 24GB HBM3 Gen2. Micron is dubbing it as the most advanced in the market currently, and its HBM3 will be able to speed up the development of generative AI.
First and foremost, although the field of AI has been around since the 1950s, it was not until very recently that computing power and the methods used in AI reached a tipping point for significant disruption and rapid advancement. Today’s applications mean that computing tasks have become more complex and strenuous, requiring faster and more efficient access to data.
Like all memory, HBM advances performance improvement and power consumption with every iteration. Take generative AI, for instance; that alone holds a tremendous need for much higher HBM. That is why, according to market experts, HBM is a segment of the memory industry that is set to grow by leaps and bounds thanks to the advent of generative AI.


In a recent research report, Trendforce noted that Micron has a tiny share of this high-growth market, with around 10%, versus an estimated 50% share for SK Hynix and 40% for Samsung. Therefore, to catch up on its major competitors in the segment, Micron Technology decided to tease its newest version of HBM for AI accelerators and high-performance computing (HPC).
In a virtual press briefing, Micron Technology said it has begun sampling the industry’s first 8-high 24GB HBM3 Gen2 memory with bandwidth greater than 1.2TB/s and pin speed over 9.2Gb/s, starting July 27, 2023. Praveen Vaidyanathan, vice president and general manager of Micron’s Compute Products Group, highlighted that the latest iteration is up to a 50% improvement over shipping HBM3 solutions.
“With a 2.5 times performance per watt improvement over previous generations, Micron’s HBM3 Gen2 offering sets new records for the critical AI data center metrics of performance, capacity, and power efficiency,” he added.
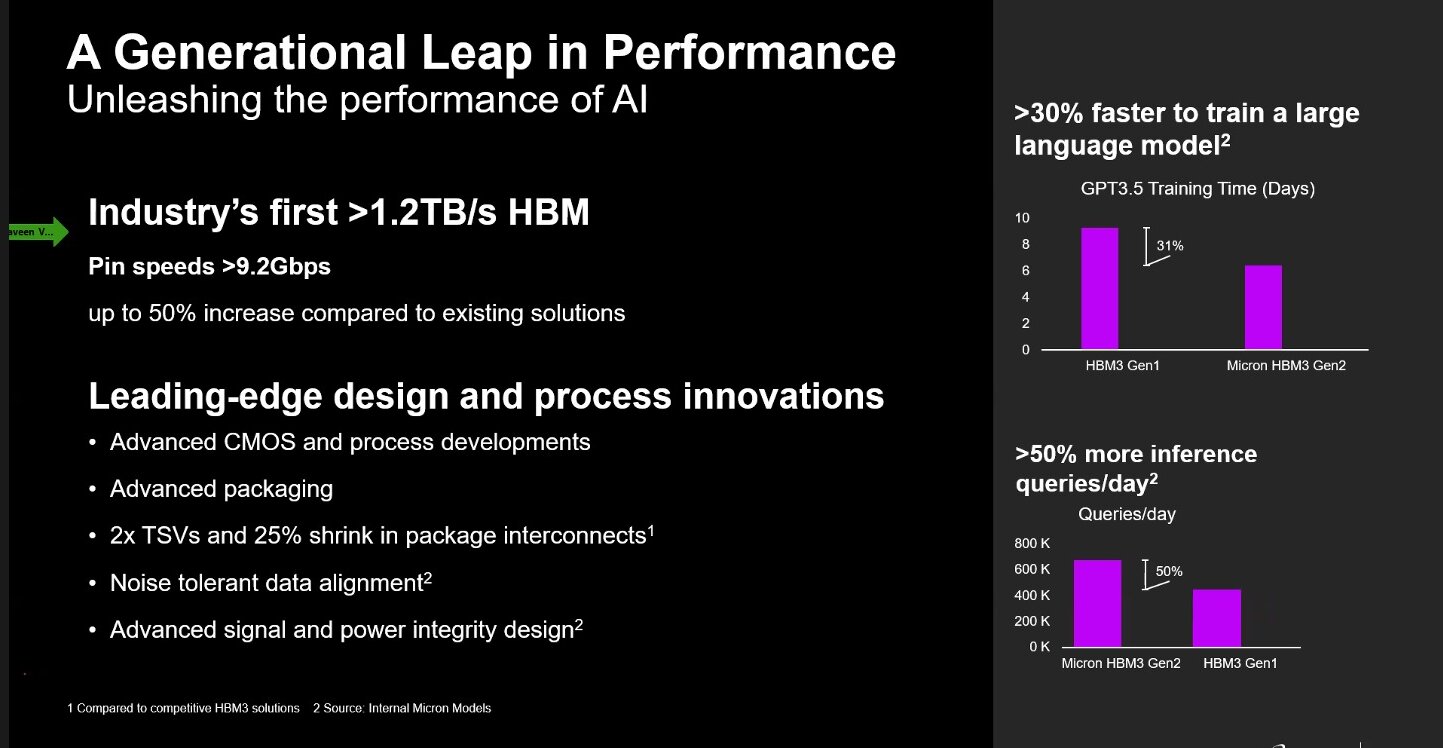
Unleashing the performance of AI. Source: Micron Technology
Most importantly, these Micron improvements reduce training times of large language models like GPT-4 and beyond, deliver efficient infrastructure use for AI inference, and provide superior total cost of ownership (TCO), Micron said in its statement.
HBM3 Gen2 by Micron Technology in the age of ChatGPT
Because of its costs and complexity, HBM was only a tiny niche market until this year. Research publication Trendforce forecasts HBM demand will soar by 60% this year, with at least another 30% growth forecast for 2024. That being said, Micron decided to develop HBM3 Gen2 with performance-to-power ratio and pin speed improvements critical for managing the extreme power demands of today’s AI data centers.
“The improved power efficiency is possible because of Micron advancements such as doubling of the through-silicon vias (TSVs) over competitive HBM3 offerings, thermal impedance reduction through a five-time increase in metal density, and an energy-efficient data path design,” the company’s statement reads.

Micron HBM3 Gen2 bringing down the cost of generative AI. Source: Micron Technology
The Micron HBM3 Gen2 solution also addresses increasing demands in generative AI for multimodal, multi-trillion-parameter AI models. “With 24GB of capacity per cube and more than 9.2Gb/s of pin speed, the training time for large language models is reduced by more than 30%, resulting in lower TCO,” Vaidyanthan said.
Additionally, he added that Micron’s offering unlocks a significant increase in daily queries, enabling trained models to be used more efficiently. “Micron HBM3 Gen2 memory’s best-in-class performance per watt drives tangible cost savings for modern AI data centers. For an installation of 10 million GPUs, every five watts of power savings per HBM cube is estimated to save operational expenses of up to $550 million over five years,” he shared.
Vaidyanathan also mentioned that the foundation of Micron’s HBM solution is its industry-leading 1β (1-beta) DRAM process node, which allows a 24Gb DRAM die to be assembled into an 8-high cube within an industry-standard package dimension.
What is more interesting is that Micron will also be working on an upgrade – a 12-high stack with 36GB capacity – which will begin sampling in the first quarter of calendar 2024. Vaidyanathan said Micron provides 50% more capacity for a given stack height than existing competitive solutions.
Micron noted that it developed this “breakthrough product” by leveraging its global engineering organization, with design and process development in the United States, memory fabrication in Japan, and advanced packaging in Taiwan. When asked if the products, once ready in early 2024, will be made available for its clients in China, Micron did not respond.
The HBM3 Gen2 product development effort will be through a collaboration between Micron and TSMC. “TSMC has received samples of Micron’s HBM3 Gen2 memory and is working closely with Micron for further evaluation and tests,” Micron noted.

Micron’s roadmap
Dashveenjit Kaur
| ![]() @DashveenjitK
@DashveenjitK
Dashveen writes for Tech Wire Asia and TechHQ, providing research-based commentary on the exciting world of technology in business. Previously, she reported on the ground of Malaysia's fast-paced political arena and stock market.
READ MORE
- 3 Steps to Successfully Automate Copilot for Microsoft 365 Implementation
- Trustworthy AI – the Promise of Enterprise-Friendly Generative Machine Learning with Dell and NVIDIA
- Strategies for Democratizing GenAI
- The criticality of endpoint management in cybersecurity and operations
- Ethical AI: The renewed importance of safeguarding data and customer privacy in Generative AI applications