NVIDIA’s solution for scalable AI and LLMs. (Source – Nvidia)
How NVIDIA’s TensorRT-LLM is making AI and LLMs more accessible
- NVIDIA’s TensorRT-LLM boosts AI and LLMs efficiency with lower latency and power use.
- TensorRT-LLM boosts LLM efficiency and speed with parallelism and in-flight batching.
- TensorRT-LLM solves several issus with deploying LLMs.
As artificial intelligence (AI) continues to evolve, one of its most compelling advancements comes in the form of large language models (LLMs). These computational behemoths have redefined the boundaries of machine learning, opening up unprecedented avenues in everything from natural language processing to real-time decision-making.
However, this leap in capability doesn’t come without its share of challenges. Complexity, scalability, and the demand for high-performance computing resources can turn the deployment of these revolutionary models into a daunting endeavor. But what if there were a solution that could effortlessly navigate these challenges while unlocking the full potential of LLMs?
NVIDIA has stepped up to this challenge by partnering with industry pioneers like Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (now part of Databricks), OctoML, Tabnine, and Together AI. Their collaborative goal is clear: to accelerate and streamline the deployment of large language models, making them more accessible and efficient.
The product of this collaboration is NVIDIA’s soon-to-be-launched open-source software, NVIDIA TensorRT-LLM. Designed to be the bridge between complexity and usability, this software package integrates the TensorRT deep learning compiler and introduces specialized kernels, data pre-processing and post-processing functionalities.
It also comes with features that allow for seamless operations across multiple GPUs and nodes. In simpler terms, TensorRT-LLM aims to empower developers to harness the true power of large language models without the need to be experts in high-level programming languages like C++ or NVIDIA’s CUDA.


By taking the complexity out of deploying LLMs, TensorRT-LLM could act as a catalyst to fuel the next phase of AI innovation.
Let’s delve into how TensorRT-LLM is addressing the technical nuances that often hinder the performance and cost-efficiency of large language models.
Latency, power, and accessibility with TensorRT-LLM
To tackle the technical challenges of deploying large language models, TensorRT-LLM offers a suite of solutions. One of the major issues is latency, which becomes a bottleneck, especially in real-time applications like chatbots or voice assistants. TensorRT-LLM addresses this by employing several optimization strategies, including layer fusion, precision calibration, and kernel auto-tuning. These strategies are further enhanced by specialized Tensor cores in NVIDIA GPUs, significantly reducing the time it takes to process inputs and generate outputs.
Another challenge is energy consumption, a concern both from a cost and an environmental standpoint. TensorRT-LLM is optimized to maximize computational efficiency per unit of power consumed, thus mitigating this issue as much as is currently possible.
Furthermore, the requirement of specialized hardware with extensive memory and processing capabilities often limits the accessibility of large language models.
TensorRT-LLM counteracts this through features like model parallelism, which divides the model into smaller segments that run simultaneously across multiple GPUs. Additional features like in-flight batching and quantization further refine hardware utilization, making TensorRT-LLM a robust and comprehensive solution to the challenges of deploying large language models.
MosaicML, for instance, was able to add the features it needed into TensorRT-LLM, which it’s integrated into its own inference serving. Naveen Rao, vice president of engineering at Databricks, praised its user-friendliness, saying the software “provides a hassle-free way to achieve state-of-the-art LLM serving performance.”
Article summarization is just a single use-case for large language models. Recent benchmarks show that TensorRT-LLM substantially improves performance on NVIDIA’s latest Hopper architecture.
Data from tests on article summarization using NVIDIA A100 and H100 GPUs and the CNN/Daily Mail dataset show significant speed improvements. Specifically, the H100 outperforms the A100 by a factor of four, and this speed increases eightfold when incorporating TensorRT-LLM features like in-flight batching.
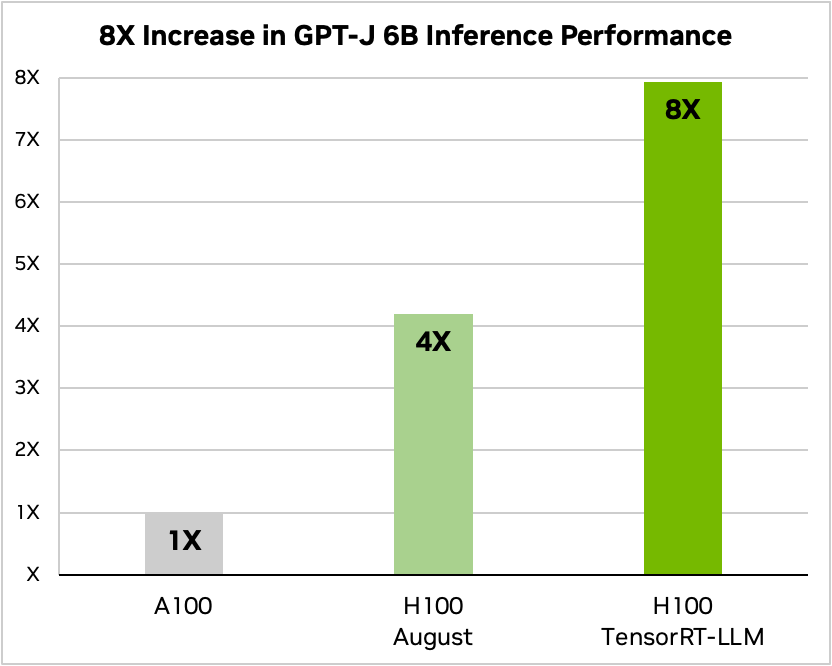
GPT-J-6B A100 compared to the H100 with and without TensorRT-LLM. (Source – Nvidia)
Furthermore, TensorRT-LLM amplifies the inference speed of Meta’s popular Llama 2 language model by 4.6 times compared to A100 GPUs.
The landscape for large language models is evolving at a rapid pace, introducing a variety of new model architectures. The most advanced of these, like Meta’s Llama 2, require coordinated multi-GPU operations to provide real-time responses. Previously, developers had to manually divide models and synchronize their execution over multiple GPUs.


TensorRT-LLM automates this process through tensor parallelism, allowing for efficient, large-scale inference without requiring manual intervention or model alterations.
As new model architectures emerge, TensorRT-LLM provides open-source support for optimizing them with the latest NVIDIA AI kernels. This includes advanced features like FlashAttention and masked multi-head attention, among others.
The software also comes with optimized versions of popular large language models currently in use, which can be easily implemented through its Python API. This enables faster and more precise customization of language models for a wide array of industries.
Overcoming dynamic workload challenges
The versatility of today’s large language models makes them suitable for a broad range of tasks. However, this adaptability complicates the effective parallelization of tasks, leading to uneven completion times.
To tackle this, TensorRT-LLM includes a feature called in-flight batching, which adjusts to these dynamic workloads. This approach boosts GPU utilization and at least doubles throughput in real-world tests, thus reducing the Total Cost of Ownership (TCO).
Typically, large language models contain billions of weights and activations, represented in 16-bit floating-point formats. However, during inference, most can be approximated effectively with lower precision formats, like 8-bit integers, thanks to modern quantization techniques.

An X user tweeted on how it will revolutionize LLM inference. (Source – X)
NVIDIA’s H100 GPUs, when used with TensorRT-LLM, allow an easy transition to a new FP8 data format. That reduces memory requirements without compromising model accuracy and is made possible through the Hopper Transformer Engine technology.
The all-in-one solution for the future of LLMs and AI
Large language models are experiencing rapid growth and diversification, expanding their applications and adoption across industries as they go. They are revolutionizing data centers by offering better performance and cost-efficiency.


For successful deployment, users should consider multiple factors like model parallelism, pipeline design, and scheduling techniques. The need for a computational platform that supports mixed precision without sacrificing accuracy is also crucial.
TensorRT-LLM offers an all-in-one solution through its Python API, bundling TensorRT’s deep learning compiler, specialized kernels, and both pre- and post-data processing, along with seamless multi-GPU and multi-node communication. This equips developers with the tools they need for efficient large language model inference in production environments.
READ MORE
- 3 Steps to Successfully Automate Copilot for Microsoft 365 Implementation
- Trustworthy AI – the Promise of Enterprise-Friendly Generative Machine Learning with Dell and NVIDIA
- Strategies for Democratizing GenAI
- The criticality of endpoint management in cybersecurity and operations
- Ethical AI: The renewed importance of safeguarding data and customer privacy in Generative AI applications